
前言:
前面一章讲了 Scrapy 安装 ,
现在总结一下 Scrapy框架基本使用
目录:
指令介绍:
打开 cmd 窗口 输入 scrapy -h 即可查看指令
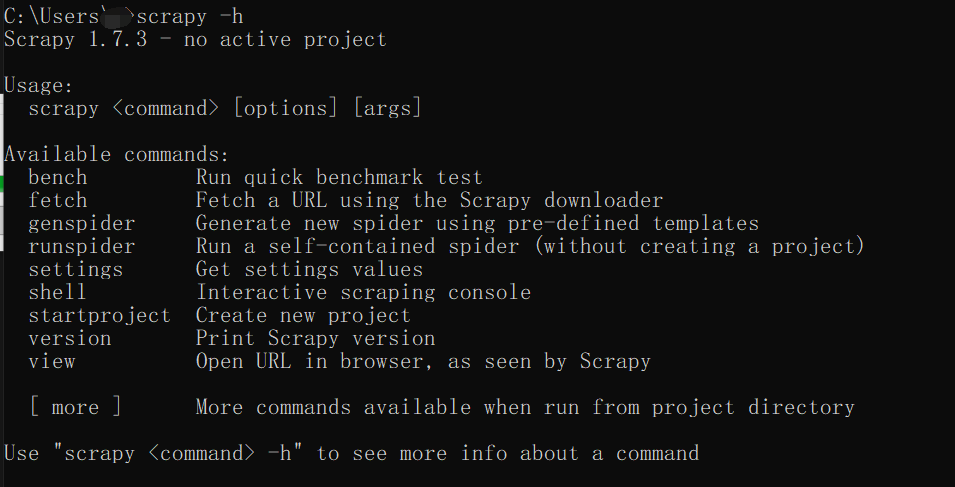
| 指令 | 功能 |
|---|---|
| bench | 项目指令,一般在项目里面运行的指令 |
| fetch | 获取某个网页的信息,使用此指令可以网页到本地 |
| genspider | 创建爬虫文件,而不是爬虫项目 |
| runspider | 运行爬虫 |
| settings | 查看爬虫对应的配置信息 |
| shell | 可以启动爬虫的交互终端,进入一个交互式窗口 |
| startproject | 创建一个爬虫项目 |
| version | 查看爬虫的版本信息 |
| view | 可以实现下载某个网页并用浏览器查看功能 |
其他的就不多介绍了。
目录结构:
下面来了解一下爬虫的目录结构
假设我们在 D 盘 下的 scrapy 目录下创建一个爬虫项目 ,名字叫 demo 吧
这里我们需要使用命令 startproject 来创建
命令:
scrapy startproject demo
这样就创建好了。
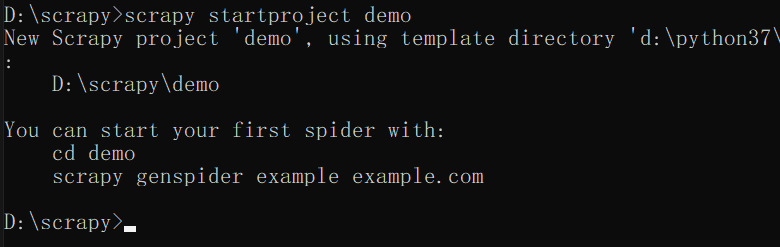
打开 demo 后,里面有两个文件,
一个是爬虫核心目录文件,
另外一个是爬虫配置文件。

接下来看看 核心目录
__pycache__ 是缓存目录
spiders 文件夹放的是爬虫文件,一个爬虫项目里面可以有多个文件
__init__.py 是初始化文件
items.py 是定义爬取目标,如何去爬取的文件
middlewares.py 是中间件文件,比如爬取一个目标,中间要经过什么,使用代理或者其他的,都在这个文件里设置
pipelines.py 是爬后数据处理文件,爬取数据后怎样的一个处理方式就是这个文件来工作
settings.py 是爬虫设置文件,假如不想遵守 robots 文件协议,可以在这里面设置

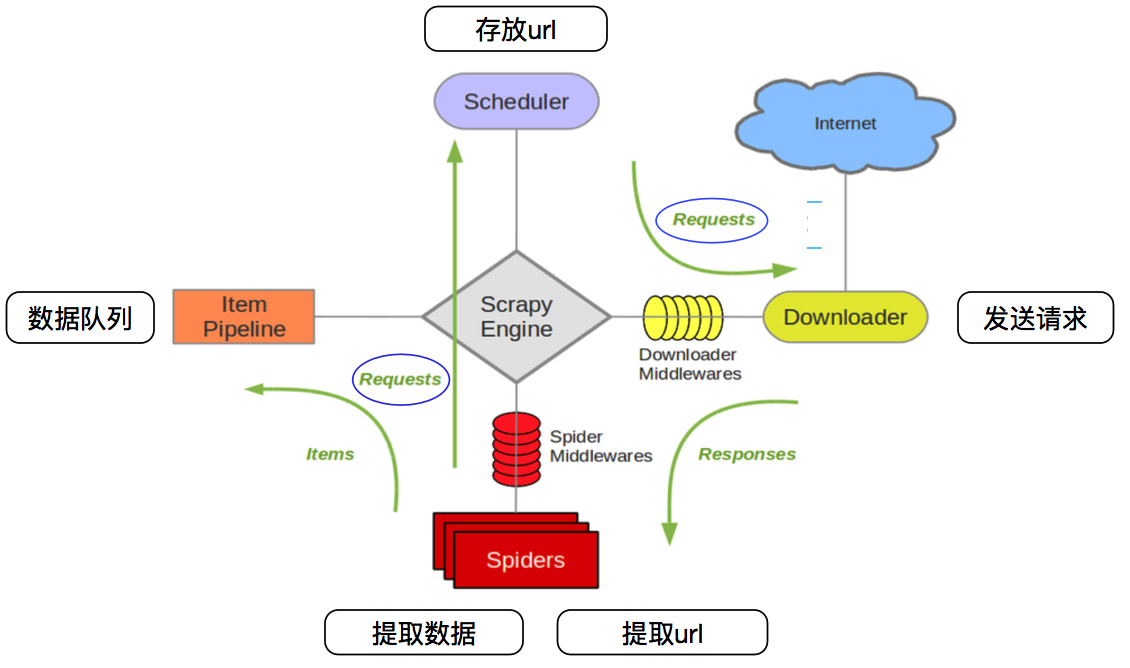
爬虫工作流程:
首先定义一个爬取目录 item ,
然后由爬虫文件 spiders 向这些目标发起请求 ,
Scrapy Engine 意思是爬虫工作引擎
Scheduler 是任务队列
接到任务后,就去 intemet 上爬取目标
然后再返回 spiders 处理这些信息
大概就是这么一个流程
如果中间需要走什么代理,那么 middlewares 就可以了
这里的话就是一些简单的操作了
主要是查看一些信息
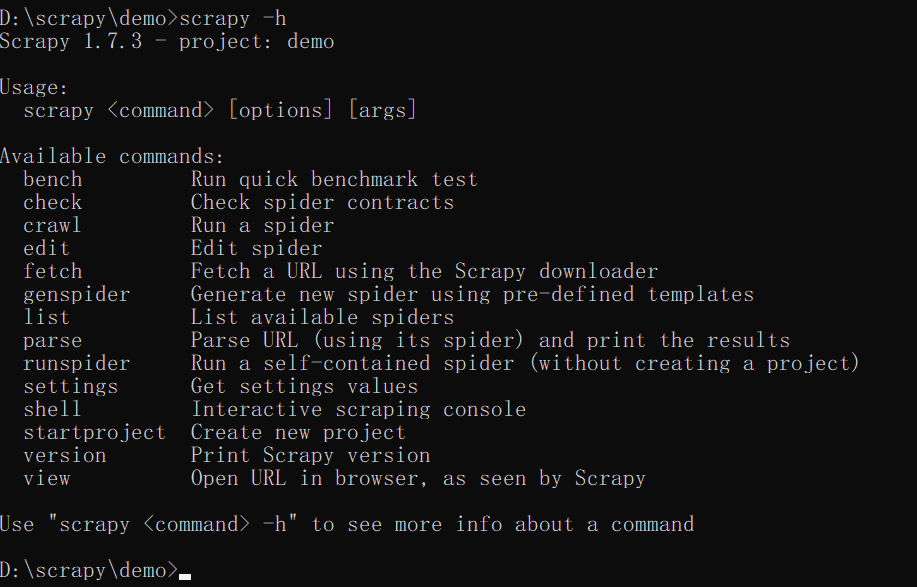
项目指令:
项目指令就是在爬虫项目里面才能使用的指令
首先我们进到爬虫项目里面
然后输入命令
scrapy -h
然后你就会发现多出来几个指令
check , crawl ,edit , list
check 检查爬虫文件是否合规
crawl 运行某个爬虫文件
edit 编辑某个爬虫文件
list 展示当前爬虫项目下,那些可以使用的爬虫文件
fetch 获取某个网页的信息
不过这个指令不是项目指令
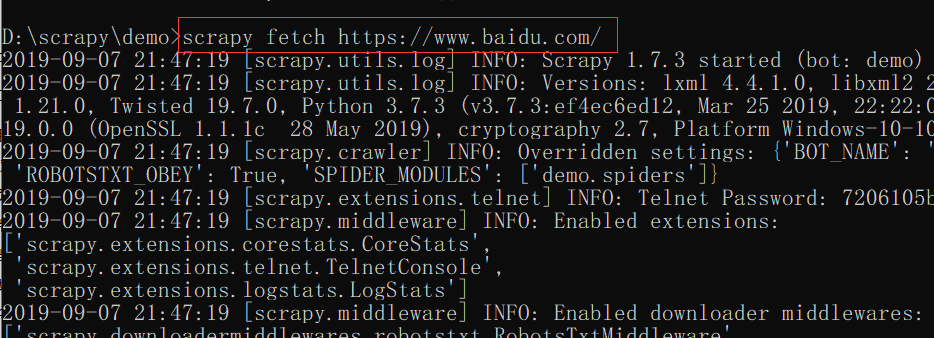
fetch 使用方法:
scrapy fetch https://www.baidu.com/ # 比如要获取百度网页信息
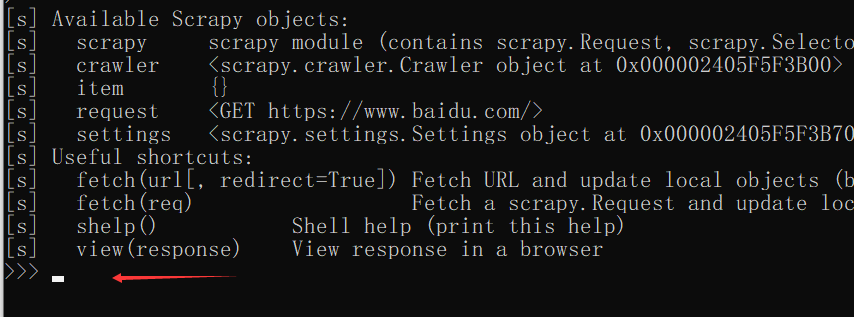
shell 使用方法:
scrapy shell https://www.baidu.com/ # 使用交互方式爬取百度网页信息
爬取完后就进入了交互式页面 。
总结:
基础就先这样吧!!