
前言:
爬取 csdn 博客
目录:
爬取csdn博客:
直接来吧,简单粗暴,
假设我们要爬取 python 专栏的文章,
我们首先要查看他链接的规律,先抓取他的链接,
查看源代码搜索第一条内容,看看他在哪里。
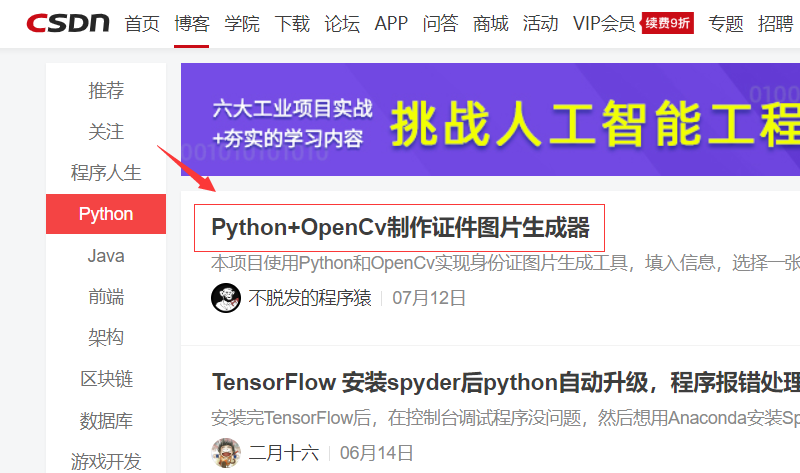
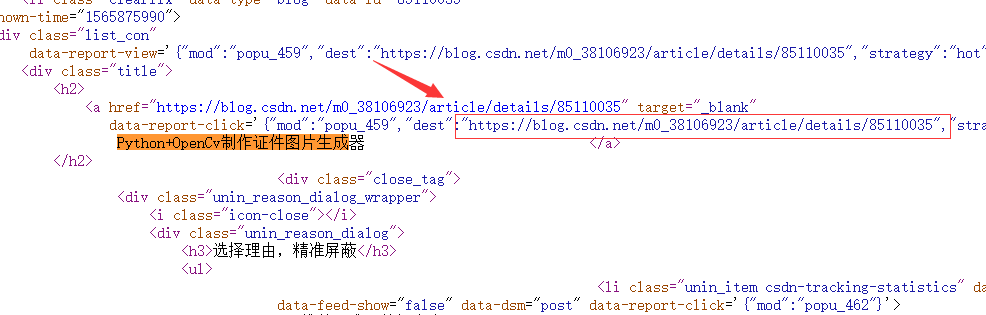
我们知道他的链接在这个位置 {"mod":"popu_459","dest":"
我们查找一下其他的标题,发现链接依旧在这个位置
那么我们就可以根据这个规律来抓取链接了
跟之前的方法一样,
首先使用 urllib.request.urlopen() 函数来打开链接,
然后再通过正则表达式去抓取链接
代码:
import urllib.request
import re
url = "https://blog.csdn.net/nav/python"
data = urllib.request.urlopen().read().decode("utf-8","ignore") # ignore 的意思是如果编码出错也强行编码
path = '{"mod":"popu_459","dest":"(.*?)",'
All_link = re.compile(path).findall(data)
for i in range(0,len(All_link)):
this_link = All_link[i]
print(this_link)
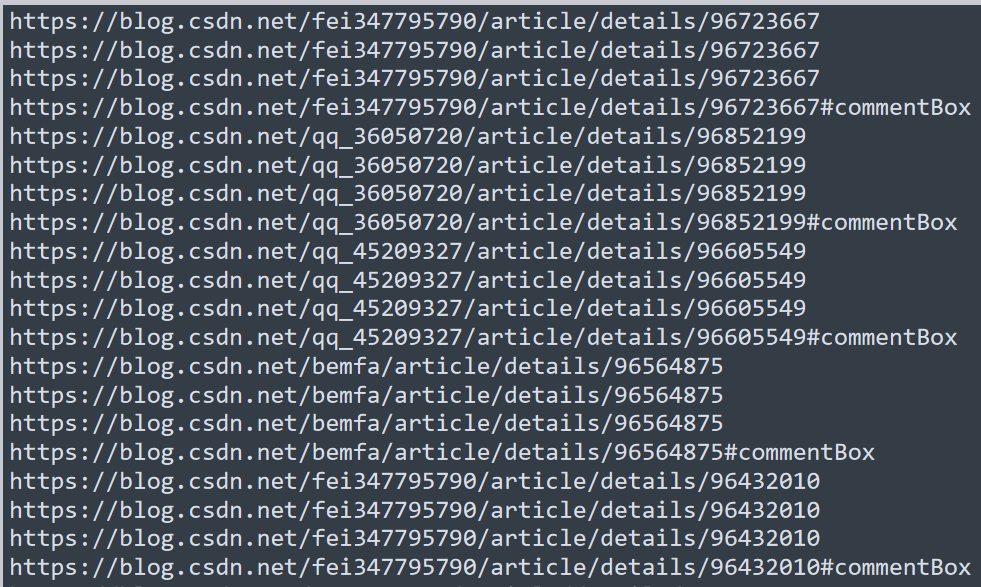
运行后就是这个样子
我们也可以将这些文章保存到本地,
使用 urllib.request.urlretrieve() 方法
代码:
import urllib.request
import re
url = "https://blog.csdn.net/nav/python"
data = urllib.request.urlopen(url).read().decode("utf-8","ignore")
path = '{"mod":"popu_459","dest":"(.*?)",'
All_link = re.compile(path).findall(data)
for i in range(0,len(All_link)):
this_link = All_link[i]
urllib.request.urlretrieve("D:/link/"+str(i)+".html")
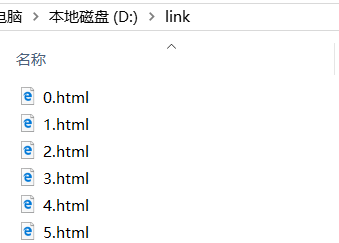
运行后就成功将文章抓取到本地 D 盘 下的 link 文件夹下面
记得先创建 link 文件夹 ,不然会报错
总结:
先这样吧!!!