
前言:
爬取豆瓣出版社名字
目录:
爬取豆瓣出版社名字:
套路还是一样的,现在来爬取豆瓣出版社名字
就是这个东西,他在 div 里面
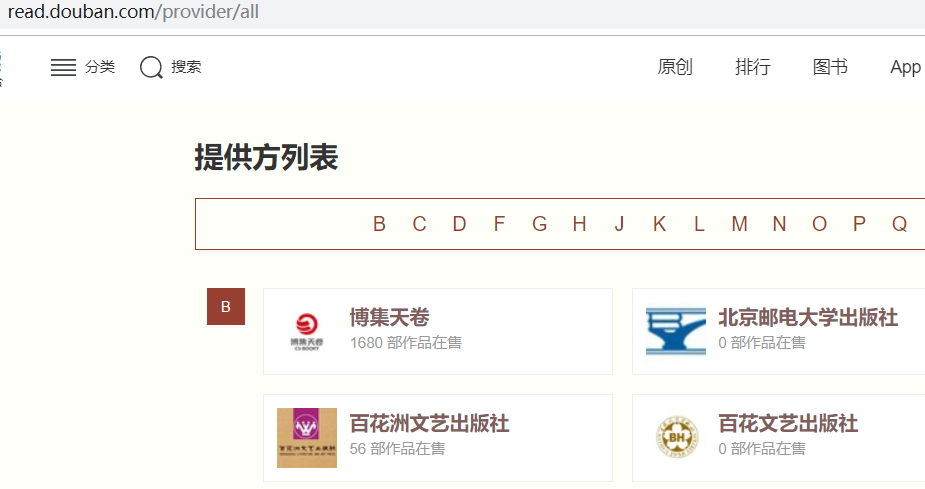

跟爬取 CSND 那个一样,写个正则就可以了
虽然爬取出版社名字豆瓣没有屏蔽爬虫,
但是还是来练习模拟浏览器请求吧
设置时间是防止请求过大
代码:
import urllib.request
import re
import time
url = "https://read.douban.com/provider/all"
headers = (
"User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
)
opener = urllib.request.build_opener()
opener.addheaders = [headers]
data = opener.open(url).read().decode("utf-8","ignore")
path = '<div class="name">(.*?)</div>'
All_press = re.compile(path).findall(data)
for i in range(0,len(All_press)):
this_press = All_press[i]
print(this_press)
time.sleep(0.5)
运行效果就这样

总结:
如果怕请求出错的话,
可以使用 try except 方法来捕获异常