
前言:
Python 正则表达式
目录:
通用字符:
| 字符 | 功能 |
|---|---|
| \d | 匹配数字,0-9 |
| \D | 匹配非数字,也就是匹配不是数字的字符 |
| \s | 匹配空白符,也就是 空格 \tab |
| \S | 匹配非空白符,跟 \s 相反 |
| \w | 匹配数字、字母、下划线, a-z, A-Z, 0-9, _ |
| \W | 匹配非数字、字母、下划线 |
下面举个粟子:
import re
string = 'abcd12345efj' # 字符串
path = "\w\d\d\d" # 正则表达式,匹配一个字母后面有3个数字的字符串
resut = re.search(path,string) # 正则表达式
print(resut)
>>> 输出 <re.Match object; span=(3, 7), match='d123'>
原子表:
直接来粟子
import re
string = 'abcd12345efj' # 字符串
path = "a[bcd]" # 括号内,满足其一即可
resut = re.search(path,string)
print(resut)
>>> 输出 <re.Match object; span=(0, 2), match='ab'>
ab 满足了括号内其中一个,
a[bcd] 表示 ab、ac、ad 只要有一个满足就行了
再举个:
import re
string = 'abcd12345efj' # 字符串
path = "a[^bcd]" # 除了 ab、ac、ad ,其他的匹配
resut = re.search(path,string)
print(resut)
>>> 输出 <re.Match object; span=(0, 2), match='ab'>
如果在 [] 内出现 ^ ,则表示非的意思
元字符:
| 字符 | 功能 |
|---|---|
| .(点) | 表示除换行外任意一个字符 |
| ^ | 如果不在原子表里面,则表示匹配开始位置 |
| $ | 匹配结束位置 |
| * | 匹配0次或者多次,可有可无 |
| + | 匹配至少1次 |
| ? | 匹配1次或者0次,要么有1次,要么没有 |
| {n} | 匹配前一个字符出现n次 |
| {n,} | 匹配前一个字符至少出现n次 |
| {n,m} | 匹配前一个字符出现n到m次 |
| |
模式选择符,表示或 |
| () | 模式单元 |
例:
import re
string = 'abcd12345efj'
path = "a....."
resut = re.search(path,string)
print(resut)
>>> 输出 <re.Match object; span=(0, 6), match='abcd12'>
.(点) 表示除换行外任意一个字符
例2:
稍微将字符串变换一下
import re
string = 'abcdddd12345efj'
path = "abcd+"
resut = re.search(path,string)
print(resut)
>>> 输出 <re.Match object; span=(0, 7), match='abcdddd'>
这里 d+ 表示后面出现 1次或多次d
而不是任意字符
例3:
import re
string = 'abcdddd12345efj'
path = "abcd{4}"
resut = re.search(path,string)
print(resut)
>>> 输出 <re.Match object; span=(0, 7), match='abcdddd'>
{4} 表示匹配4个d,包含前面的d
如果是 {3} 就匹配出3个d
模式修正符:
所谓的模式修正符,即可以在不改变正则表达式的情况下,
通过模式修正符改变正则表达式的含义,
从而实现一些匹配结果的调整等功能。
| 字符 | 功能 |
|---|---|
| I | 匹配时忽略大小写 (常用) |
| M | 多行匹配 (常用) |
| L | 本地话识别匹配 |
| U | unicode |
| S | 让 .(点) 匹配,包括换行符 (常用) |
例:
import re
string = 'Python'
path = "py"
resut = re.search(path,string,re.I)
print(resut)
>>> 输出 <re.Match object; span=(0, 2), match='Py'>
使用方法为:
resut = re.search(正则表达式,要查找的字符串,模式修饰符)
贪婪模式和懒惰模式:
贪婪模式的核心点就是尽可能多的匹配,
而懒惰模式的核心点就是尽可能少的匹配。
贪婪模式:
.* 默认为贪婪模式
import re
string = 'boyboyboy'
path = "b.*y"
resut = re.search(path,string,re.I)
print(resut)
>>> 输出 <re.Match object; span=(0, 9), match='boyboyboy'>
懒惰模式:
.*? 加问号为懒惰模式
import re
string = 'boyboyboy'
path = "b.*?y"
resut = re.search(path,string,re.I)
print(resut)
>>> 输出 <re.Match object; span=(0, 3), match='boy'>
懒惰模式相比贪婪模式匹配更为精准
贪婪模式匹配比较模糊。
正则表达式函数:
常用的函数有:
| 字符 | 功能 |
|---|---|
| re.match | 从头开始匹配 |
| re.search | 任意一个位置都可以匹配 |
| re.compile | 全局匹配函数,格式: re.compile(正则表达式).findall(要查找的字符串) |
| findall | 表示为所有 |
例:
import re
string = '3432bayasdd343boyfghddbsy123'
path = "b.*?y"
resut = re.compile(path,re.I).findall(string)
print(resut)
>>> 输出 ['bay', 'boy', 'bsy']
只要满足 b 什么什么 y 的,全部都输出
实例1:匹配 .com 和 .cn 网址
假如我们需要抓取 <a> 标签里面的网址,
<a href='https://www.baidu.com/'>百度首页</a> ,
我们可以这样写正则表达式,
第一个 [a-zA-Z] 表示匹配 协议名称 ,比如 https
如果换成 ftp 或者其他协议也能够匹配 ,
第二个 [\S] 表示匹配 www 或者其他的,当然不可能是空白符号,
也不存在有空白符的 url,其次 例如: https://xxx.com 这种没有www的,也能匹配
| 第三个 **[.com | .cn]** 这个就比较好理解了,就是匹配 .com 或者 .cn 的网站 |
代码:
import re
string = "<a href='https://www.baidu.com/'>百度首页</a>"
path = "[a-zA-Z]+://[\S]*[.com|.cn]/"
resut = re.compile(path,re.I).findall(string)
print(resut)
>>> 输出 ['https://www.baidu.com/']
实例2:匹配手机号
这里讲两种电话号码,
一种是3位数字的区号,另外一种是4位数字的区号
这个正则表达式应该很好理解,
\d{3}-\d{8} 就是匹配3位数字的电话号码,比如:010-88888888
import re
string = "abcde010-88888888fghjkl0222-9999999cmbvc"
path = "\d{3}-\d{8}|\d{4}-\d{7}"
resut = re.compile(path,re.I).findall(string)
print(resut)
>>> 输出 ['010-88888888', '0222-9999999']
实例3:简单爬虫编写
这里使用 urllib 库
urlopen() 函数用来打开 url ,
read() 函数用来读取内容
下面代码就会输出网页的全部内容(源码)
import urllib.request
url = 'http://edu.csdn.net'
resut = urllib.request.urlopen(url).read()
print(resut)
下面来提取课程标题
随便打开一个课程,
假设我们想要获取课程标题,那么我们就需要使用正则表达式了
首先先用 F12 看看标题在那个标签下,有什么规律
现在我们发现他在 h1 标签里面 ,
然后我们就需要从 h1 标签里面提取出来。
然后正则应该是 <h1>(.*?)</h1> ,(.*?) 这个括号表示要提取的内容
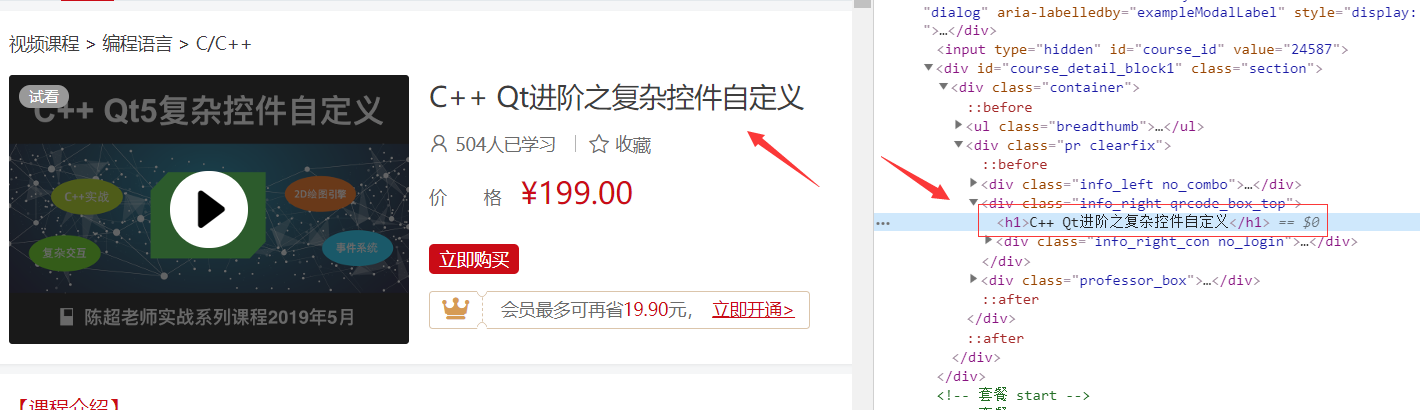
下面是代码:
运行后就提取出来了
import urllib.request
import re
url = 'https://edu.csdn.net/course/detail/24587?utm_source=banner'
data = urllib.request.urlopen(url).read().decode()
path = '<h1>(.*?)</h1>'
resut = re.compile(path).findall(data)
print(resut)
>>> 输出 ['C++ Qt进阶之复杂控件自定义']
总结:
就先到这里吧,
需要多加练习。